Logistic Regression의 확장
Logistic Regression은 참 혹은 아니오 같은 이분법 분류만 가능한 Classification기법 이였다. 그러나 Regression을 활용하여 더 많은 수의 이산적 수치를 구분 할 수 있는 모델이 있을까? 답은 가능하다.
Logistic Regression 모델을 중첩하여 2개 이상의 결과를 가진 데이터를 구분하는 모델을 만들어 보자.
Decision Boundary
2개 이상의 결과를 구분하기 위한 Softmax를 살펴보기 이전에 Decision Boundary라는 것을 살펴보자. 이는 Classification시 데이터의 구분을 보다 쉽게 이해하기 위한 그래프의 종류이다. 우선 이해를 위해 아래의 Sigmoid 그래프를 보자. 이 그래프의 수식은 아래와 같다.
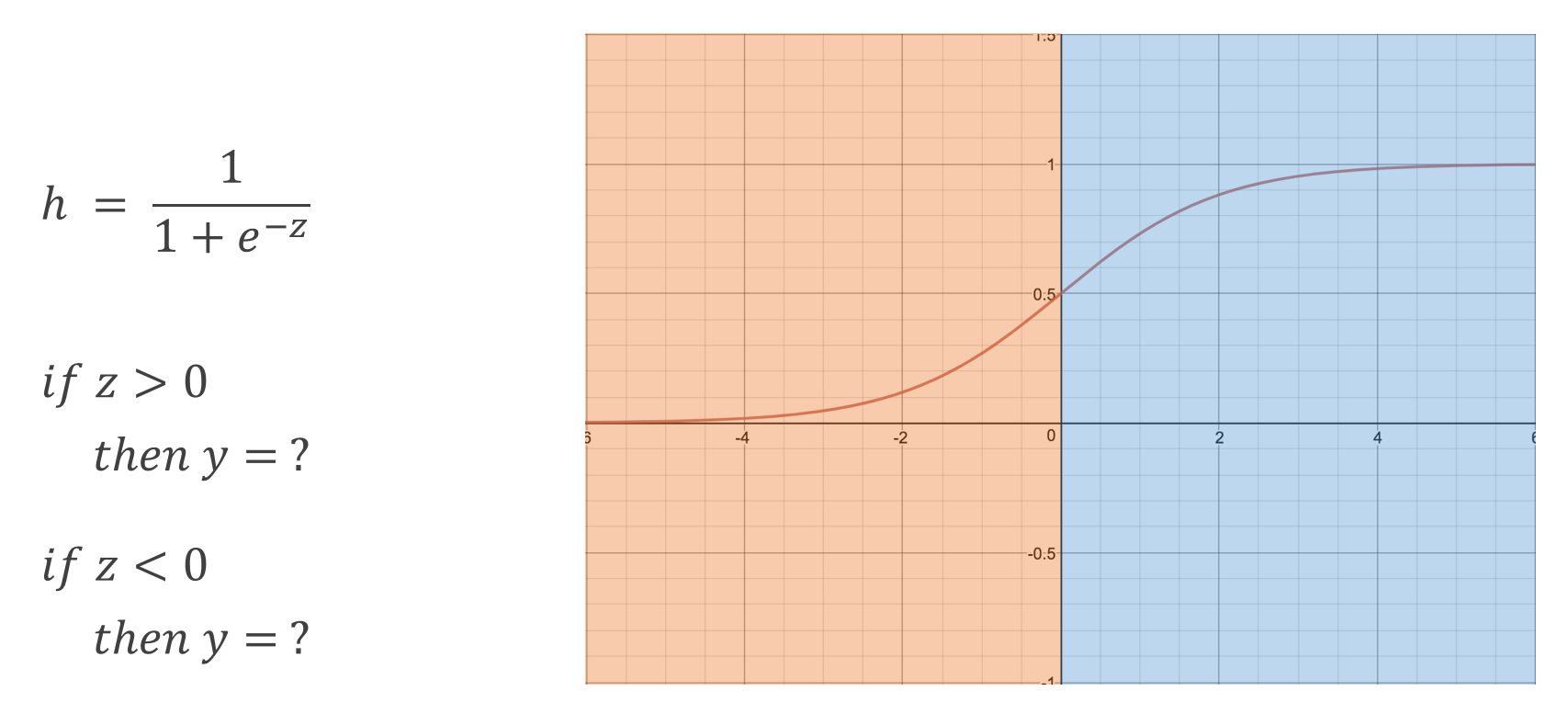
이 Sigmoid 함수는 입력값 z를 받고 결과 h를 도출하고 있다. 결과는 이전에 공부한대로 0 ~ 1의 범주를 가지고 있다. 전과 달리 이번엔 z값에 집중해보자. 아래 Sigmoid 함수에서 붉은색 영역을 보면 z값이 0보다 작다. 이는 확률이 50%를 넘지 못함으로 결과적으로 h는 0을 갖게되고 푸른색 영역에서는 z값이 0보다 커서 확률이 50% 이상이 되어 h는 1의 값을 가지게 된다.
이전에 Logistic Regression에서 Hypothesis로 정의한 Sigmoid 함수식을 보자.
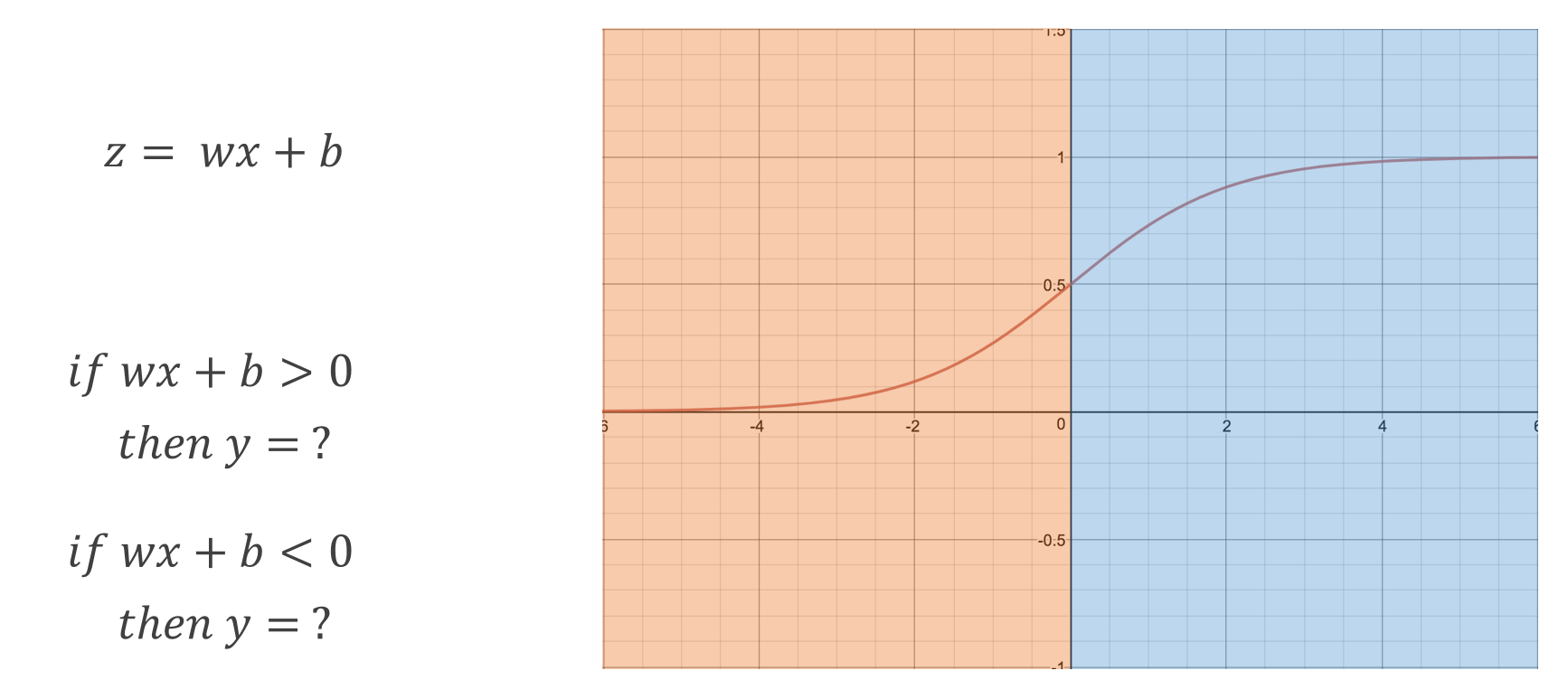
위의 예에서 z값이 0을 기준으로 결과 h값이 변하는 것을 확인했다. z값은 linear model인 wx + b값과 같음으로 이는 wx + b 기준으로 결과 h값이 변한다고 말할 수 있다. 즉 아래와 같다.
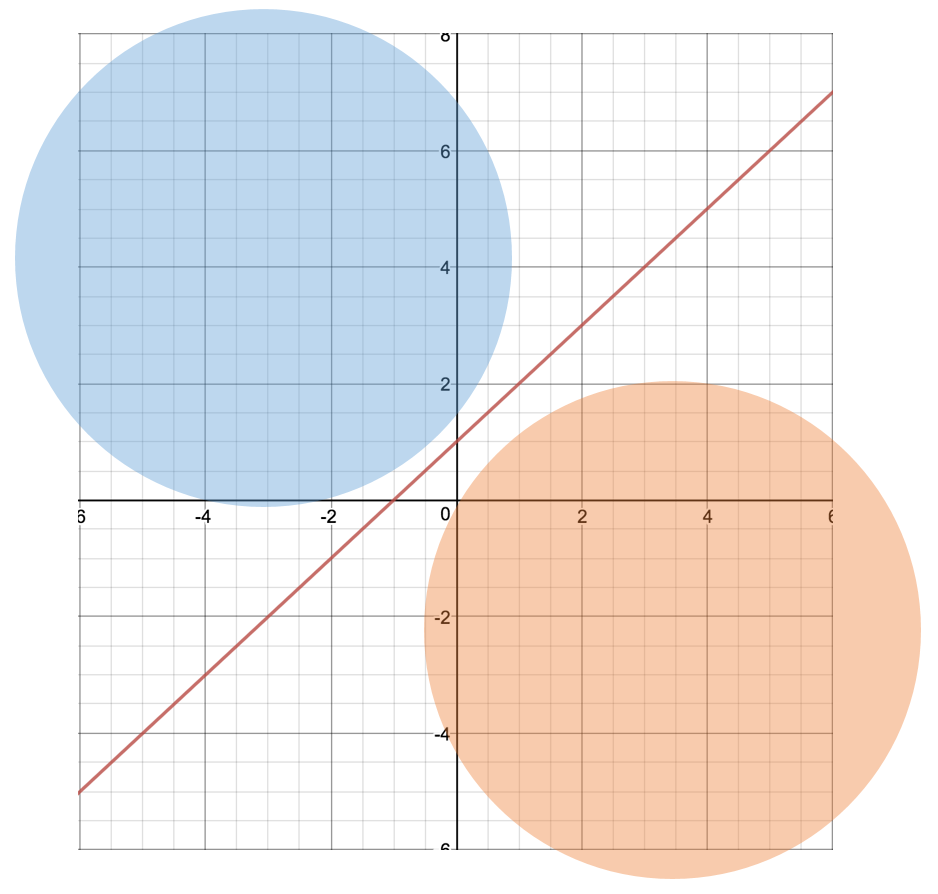
푸른색의 원이 가리키는 선형회귀 모델의 윗부분은 hypothesis의 결과값 h가 1이 되는 영역이고 반대로 붉은색 원이 가리키는 아랫 부분은 결과값 h가 0이 되는 영역이다. 이렇게 Hypothesis model에서 Activation Function을 거치지 않고 그 전의 모델을 그래프로 그려서 판단하는 것은 Decision Boundary라고 한다. 이는 때에 따라서 굉장히 문제를 직관적으로 볼수 있어 유용하다. 이제부터 볼 Softmax도 이에 해당한다.
Softmax
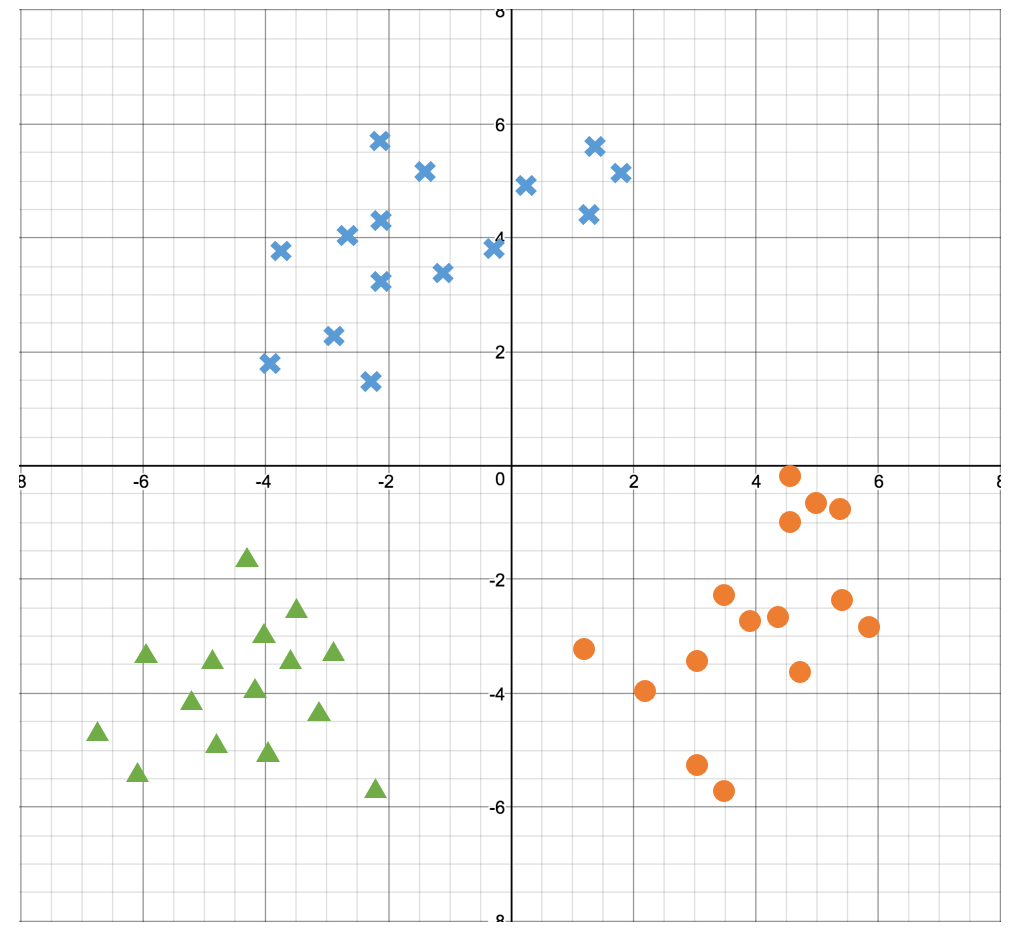
Logistic Regression은 1 혹은 0과 같이 2분법적으로만 Classification이 가능했다. 그렇다면 위의 그래프와 같이 3개의 경우의 수가 있다면 어떻게 해결해야 할까. 우리는 Softmax라고 불리는 Logistic Regression의 중첩방법으로 해결한다.
3개의 결과값을 가지는 데이터들이라면 이를 위해 총 3개의 가설을 세운다. 즉 3개의 Hypothesis model을 가진다. 각 가설은 다음과 같다.
1. 푸른색 엑스 데이터면 참 아니면 거짓.
2. 초록색 세모 데이터면 참 아니면 거짓.
3. 주황색 원 데이터면 참 아니면 거짓.
각 가설 하나 하나는 이분법적 계산을 함으로 Logistic Regression으로 구현이 가능하다. 전의 Logistic Regression의 과정대로 학습시켜 잘 표현된 모델 3개를 구현한다. 이는 아래와 같다.
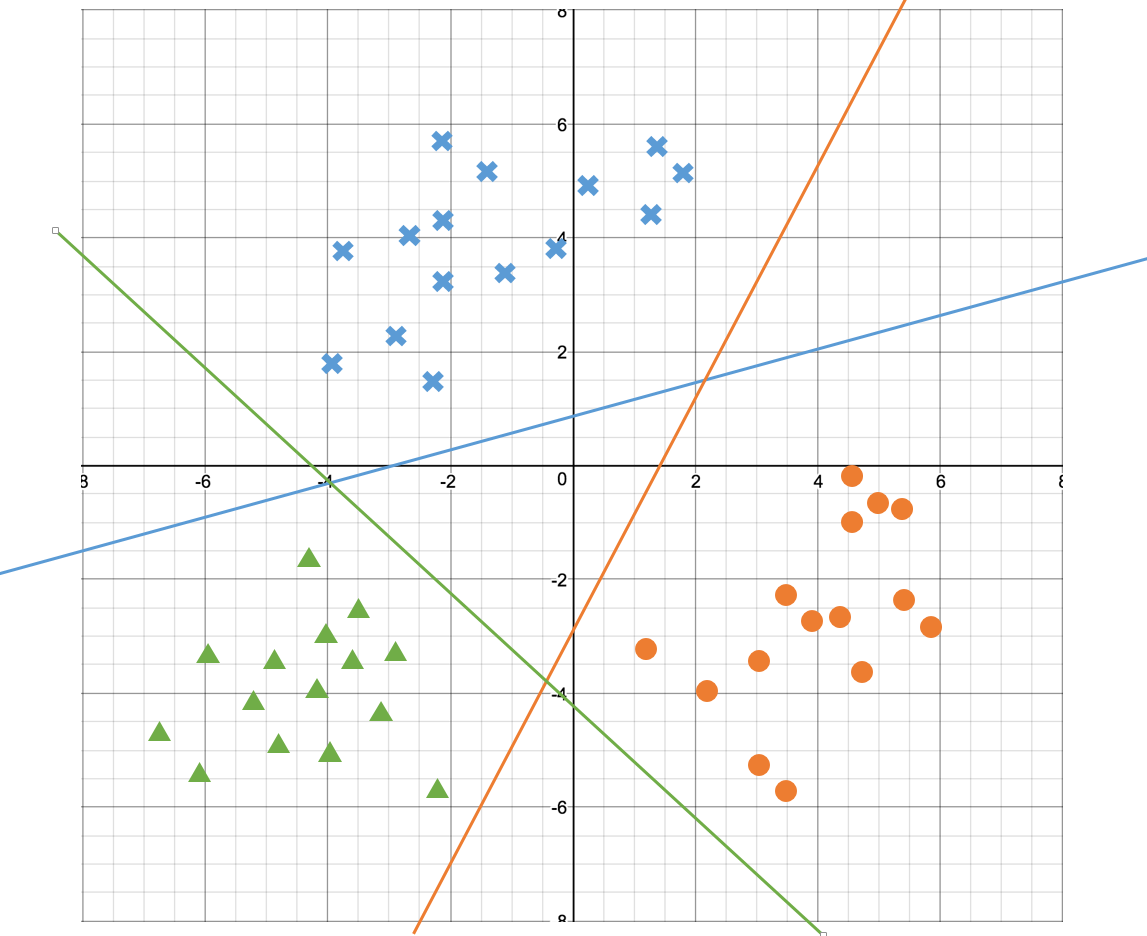
푸른색 선은 1. 푸른색 엑스 데이터면 참 아니면 거짓에 의한 모델, 초록색 선은 2. 초록색 세모 데이터면 참 아니면 거짓에 의한 모델, 3. 주황색 선은 주황색 원 데이터면 참 아니면 거짓에 의한 모델이다.
최종적으로 새로운 데이터가 어느 분류에 속하는가를 예측하기 위해서 각 모델을 통해 예측을 진행하고 가장 확률이 높게 나온 모델을 참으로 본다.