각 Data Set의 역할.
일반적으로 Overfitting을 방지하기 위해서 Data set을 3가지로 구분하여 학습을 진행한다.
1. Train Set
학습을 위한 데이터셋이다. 가장 기본적으로 사용되며 일반적으로 Data Set의 60%를 사용한다.
2. Validation Set
모델을 평가하기 위한 데이터셋이다. 하이퍼 파라미터나 Hypothesis의 결함을 발견하기 위해서 사용한다. 일반적으로 Data Set의 20%을 사용한다.
3. Test Set
Learning System의 최종 점검을 위해 사용한다. 마지막 남은 Data Set의 20%를 사용한다.
Cross Validation Set
학습 데이터의 양이 충분하지 않을 경우에는 Validation Set을 없애고 Train Set과 Test Set을 지속 번갈아 가면서 테스트를 하게 되는데 이 방법을 교차 검증(Cross Validation)이라고 부른다. 학습 데이터가 적다면 Test set의 데이터가 더욱 적어서 성능 평가시에 편향이 생기게 된다. 이를 위해 교차 검증은 모든 데이터가 최소 한 번은 테스트 셋으로 쓰일 수 있도록 계속 Iteration한다.
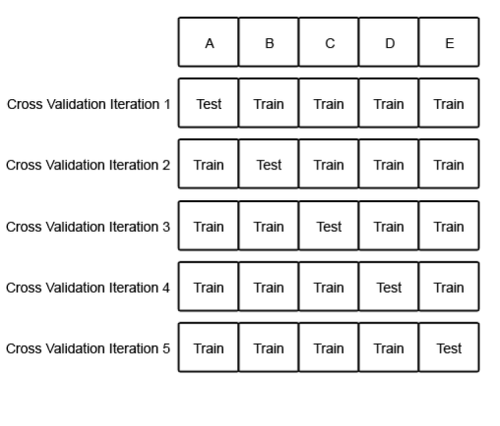
위의 예처럼 train set이 총 5개로 분할 되었다면 각 반복시점에서 한번씩은 Test Set으로 사용할 수 있도록하고 각 반복에서 얻어낸 값을 평균 내어 모델을 수정한다.